The Ask the Analyst series is a deep dive into the data by those most familiar with the CO APCD – the analysts themselves. We’ll hear about their experiences with recent analyses and answer any pressing questions that come up. Have a question for the CIVHC Analyst Team? Email it to info@civhc.org.

Name: Kristin Paulson, JD, MPH
Chief Operating Officer and General Counsel
Project Name: Standard De-Identified Data Sets
The Standard De-Identified Data Sets were created to give CIVHC a fast, secure, straightforward, and relatively inexpensive way to provide data to Change Agents that avoided the time and expense of a custom dataset request.
- What were your first steps when beginning this analysis?
We started by creating a Data Element Dictionary (DED) with all of the individual identifiers and antitrust elements removed, resulting in a dataset that was completely de-identified and posed no antitrust risk. Because HIPAA doesn’t apply to completely de-identified data, the dataset didn’t need to meet minimum necessary requirements and could be released to anyone who met the benefit to Colorado and Triple Aim requirements in the CIVHC regulation. This became the Level 1 Standard Dataset. Then we evaluated limited elements that would provide additional value to certain clients, but could only be released to certain client types due to antitrust concerns. These were tailored to provide as much value as possible to clients without creating liability concerns for CIVHC. These became the Levels 2a, 2b, and 3 standard datasets.
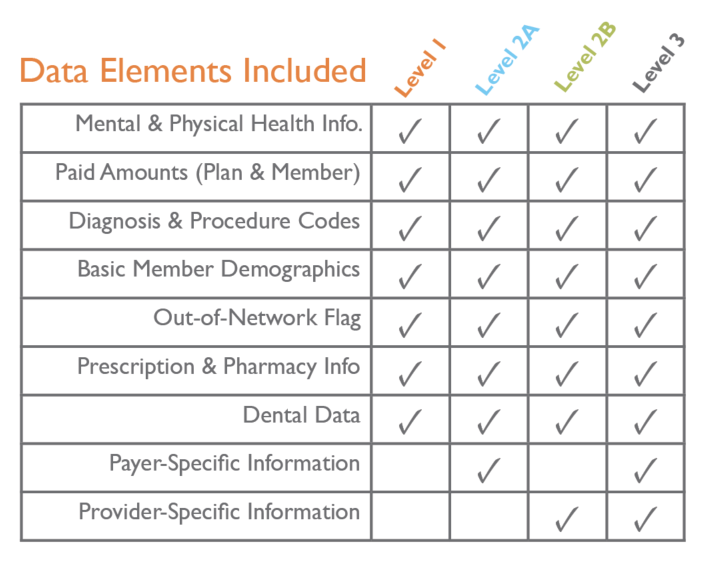
- Were there specific considerations you needed to consider based on the data?
Compliance, compliance, compliance – and data utility. We wanted to make sure that the data sets contained enough information to be useable by a broad swath of clients and stakeholders, but were also built to avoid privacy issues, HIPAA, and antitrust concerns. To this end, we looked at requests in the past to identify commonalities. We also worked to create a sequencing algorithm that allows data analysts to determine time between claims and calculate things like readmission rates or follow up without having to have access to dates of service, broadening the applicability of the datasets. In order to keep these as useable as possible, the standard datasets were run in two-year increments by line of business, back to 2012.
- What challenges did you encounter while performing the analysis? How did you overcome them?
Challenges included trying to figure out what fields needed to be eliminated to address antitrust concerns. Antitrust is a vague area of law than HIPAA and privacy law, and making decisions about what needed to be eliminated from the DEDs to minimize antitrust risk to payers took a long time and required repeated consults with outside antitrust counsel. This process took a lot of collaboration among CIVHC staff and outside consultants, multiple reviews, and feedback from the Data Release Review Committee before the DEDs were finalized.
- What else should people know?
Nothing really surprising. We had been talking about creating these standard datasets for years and it was great to finally figure out how to do them! Many different states have tried to figure out how to create standard datasets that are useable by different stakeholders and have come up short. The combination of key CO APCD data elements, such as member ID (de-identified) and provider ID (de-identified) mean that our standard datasets can all support longitudinal analyses and answer diverse questions.
We’re still learning as an organization how to let people know about this relatively affordable and fast option, but they are already one of the fastest growing, if not the fastest, growing non-public release type at CIVHC, which is very exciting.